- January 15,2017 | ISSN 1940-6967
- The National Association Of Medical Doctors


Featured Sponsors


Paying Doctors Bonuses For Better Health Outcomes Makes Sense In Theory. But Does Not Work.
By Stephen B. Soumerai and Ross Koppel
For decades, the costs of health care in America have escalated without comparable improvements in quality. This is the central paradox of the American system, in which costs outstrip those everywhere else in the developed world, even though health outcomes are rarely better, and often worse.
In an effort to introduce more powerful incentives for improving care, recent federal and private policies have turned to a “pay-for-performance” model: Physicians get bonuses for meeting certain “quality of care standards.” These can range from demonstrating that they have done procedures that ought to be part of a thorough physical (taking blood pressure) to producing a positive health outcome (a performance target like lower cholesterol, for instance).
Economists argue that such financial incentives motivate physicians to improve their performance and increase their incomes. In theory, that should improve patient outcomes. But in practice, pay-for-performance simply doesn't work. Even worse, the best evidence reveals that giving doctors extra cash to do what they are trained to do can backfire in ways that harm patients’ health.
The stakes are high. Britain, with a much different health system — single payer — has embraced pay-for-performance in a big way, spending well over $12 billion on such programs in 12 years. And pay for performance is a feature of virtually every major health program in the US.
While cost estimates are scarce, regulations intended to incentivize doctors for quality and efficiency cost physicians more than $15 billion just for documenting their actions. In yet another assault on common sense, Congress passed an enhanced pay-for-performance law ("MACRA") that went live January 1.
Blame for the wasteful embrace of pay-for-performance measures can be directed to at least two sources: First, an overreliance on economic theory in the absence of empirical testing. (Of course, performance will get better if you pay people for outcomes, an Econ 101 student might say.) Second, numerous studies have purported to show that health outcomes improve when doctors’ pay is pegged to performance outcome — yet these studies have fatal flaws.
Many such studies suffer from what’s known as “history bias.” That is, they tend to treat any positive health trend after the introduction of performance pay as the result of that payment system. But it’s often the case that the positive trend predates the introduction of the treatment.
The failure of pay for performance has been demonstrated repeatedly in scientific studies. In a recent article, we showed that much of the early research on the supposed success of pay for performance was conducted with serious research design flaws. For example, in the UK, effective treatment of high blood pressure has been increasing for years — well before pay-for-performance measures designed to improve blood-pressure treatment had begun. Doctors had both been getting better at identifying patients with high blood pressure and drug treatment regimens had been improving. But the early research inappropriately credited pay for performance with all the improvements that followed its introduction.

Consider the following graph, from a major study evaluating the United Kingdom’s pay-for-performance policy where diabetes is concerned. It purported to find a major positive effect. The red dashed line shows where the rewards program began:
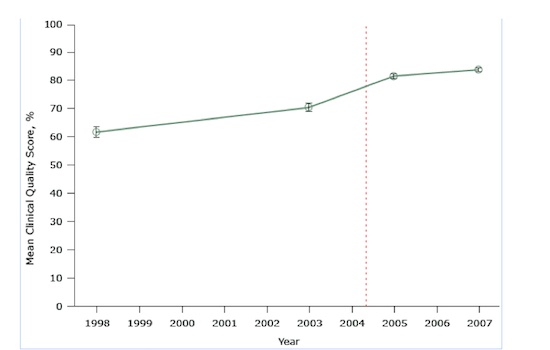
Figure 1. Mean clinical quality scores for diabetes treatment at 42 practices participating in a study evaluating pay-for-performance in the UK. The scale for scores ranges from 0 percent (no quality indicator was met) to 100 percent (all quality indicators were met for all patients).
The key problem here is that the researchers use only two data points during the long period before the program was implemented, and two data points afterward. If anything, it appears that the improvements — to the extent any are detectable by examining only two data points — may have grown less quickly after implementation of pay-for-performance. We also don’t know if any small improvements resulted from pay-for-performance or from some other changes in physicians’ practice.
The next figure illustrates a result of one of the most convincingly negative studies of the UK’s pay-for-performance policy. In this case, the treatment question involved patients with hypertension. Using a strong long-term research design and seven years of monthly data for 400,000 patients before and after the program’s implementation (84 time points), the study showed that the pay-for-performance program was introduced in the middle of a slight rise in the percentage of patients who began blood pressure treatment.
It seems clear from the trend line that pay for performance did not cause the rise:
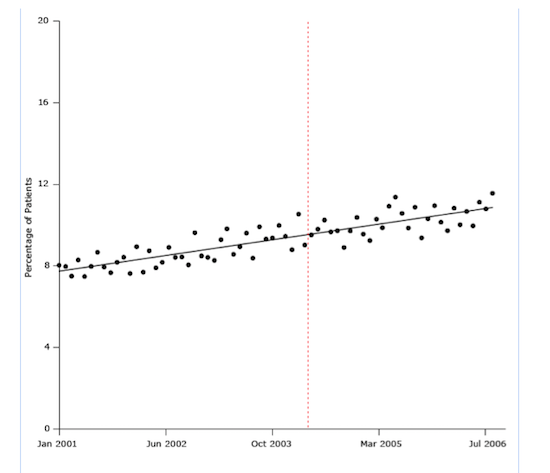
Figure 2. Percentage of study patients who began antihypertensive drug treatment from January 2001 through July 2006. The dashed line indicates when the UK’s pay-for-performance policy was implemented (April 2004).
This is a big deal: a $12 billion program that links doctors’ incomes to measures of health-care quality had no effect.

The strongest design for evaluating policies is a randomized controlled trial (RCT). In such study designs, random allocation of participants into intervention and control groups increases the likelihood that the only difference between the groups is the pay-for-performance intervention. In a recent RCT, physicians in the pay-for-performance condition were eligible to receive up to $1,024 whenever a patient met target cholesterol levels. Physicians in the control groups received no economic incentives to hit those targets.
There was no real difference in improvements between the two groups:
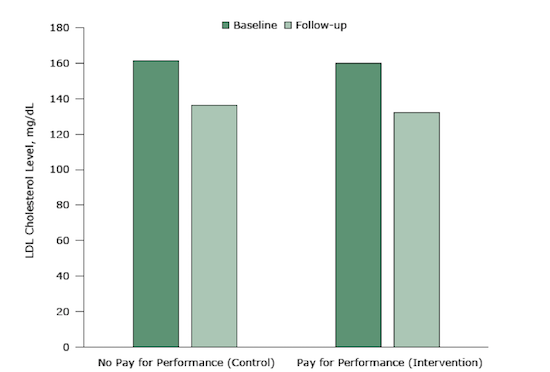
Figure 3. Mean LDL cholesterol levels at baseline and 12-month follow-up in an intervention (pay-for-performance) group and a control group (no pay-for-performance). The difference between the 2 groups was neither statistically significant nor clinically meaningful.
No study is perfect, and it’s unlikely that a single study can determine the truth. But when you single out the most rigorous systematic reviews, empirical support for pay for performance evaporates.
Why doesn’t pay for performance work?
There are a few reasons why performance incentives fail. They reward doctors for things they already do, like prescribing antihypertensive drugs. What’s more, the programs often use lousy, unreliable quality measures: For example, they might penalize doctors for not prescribing antibiotics to patients who are allergic to them.
More troubling, there is evidence that such policies may even harm patients by encouraging unethical practice. One international systematic review found — in addition to no positive effects — that pay-for-performance programs had the unintended consequence of discouraging doctors from treating the sickest and most costly patients; there’s an incentive to cherry-pick the healthiest, active, and wealthy patients.
Health professionals do not respond to economic carrots and sticks like rats in mazes. As the leading health care economist Uwe Reinhardt said, “The idea that everyone’s professionalism and everyone’s good will has to be bought with tips is bizarre.”

Some health policy experts, like Harvard public health professor Ashish Jha, have argued that the awards in pay-for-performance programs simply ought to be increased: “Make the incentives big enough, and you’ll see change,” he has said. But there’s no evidence that the program has failed because doctors aren’t being paid enough. A pay-for-performance program in the UK paid an extra $40,000 per year on average to family doctors, but it still failed to improve care.
The pattern goes deeper than flawed study design and quality measures. Policymakers too often show unbridled confidence in economic theories and models that are unsupported by evidence. Health economists aim to predict how doctors will respond to incentives, but without understanding the complex pressures they face that shape behavior — including high patient loads, incomprehensible insurance rules, increasing time demands for more and more regulatory requirements, duplicative or conflicting regulations, and documentation of often unnecessary clinical data in different and noncommunicating electronic medical records systems.
In April 2015, ignorant of decades of research, a bipartisan Congress passed a huge new law (“MACRA”) that will tie even more funding to these questionable “quality scores” beginning this month — even amid the tumult of the Obamacare debate. The government’s MACRA rules took up almost 2,400 pages of text, and physicians are already balking at the additional paperwork and screen time.
Under MACRA, doctors who opt into pay for performance are allowed to themselves choose, out of many possibilities, the six criteria on which their performance will be judged by the Centers for Medicare and Medicaid Services (CMS). Letting doctors choose their own criteria clearly lets doctors game the system for extra income, and it seems unlikely to provide any useful data — especially with almost every doctor choosing a different mix of standards.
We can do better. Researchers, policymakers, and journalists have a responsibility to understand the crucial role of robust research design. Academic journals should adopt the same research design standards used by Cochrane, the leading international medical research organization that conducts reviews of medical evidence. Cochrane weeds out the weakest studies.
Instead of a punitive incentive-and-penalty approach, policymakers should try to identify the reasons for poor performance. In contrast to numbers that can be gamed, doctors and nurses want concrete information they can use to improve care and save money. One of the most celebrated successes in American medicine involved the use of doctors, nurses, and pharmacists to counsel frail elderly people being discharged from hospitals and follow them at home to help them take their drugs and stay healthy. This program avoided costly and painful readmissions to the hospital.
We also must rethink the role of abstract economic theory and dubious economic models in policymaking. While much of human activity can be attributed to simple financial incentives, not all can nor should be. This is not just an academic argument. America spends more on medical care than any other nation but gets second-rate results. We need better research and more realistic theory to guide our massive investments in health care.
Stephen Soumerai is professor of population medicine and research methods at Harvard Medical School and the Harvard Pilgrim Health Care Institute. Ross Koppel teaches research methods and statistics in the sociology department at the University of Pennsylvania, conducts research on health care IT, and is a senior fellow at the Wharton School’s Leonard Davis Institute of Health Economics.


Articles in this issue:
- The CDC's Fictitious Opioid Epidemic, Part 1
- Paying Doctors Bonuses For Better Health Outcomes Makes Sense In Theory. But Does Not Work.
- What Primary Care Doctors Really Think About Obamacare
- How Serious Damage Is Done By Scientific Fraud-JAMA Retracts Article
- Physician Participation In Executions Must Be Stopped
- Which Physician Specialties Are Happiest?
- White-Washing A Black Box Warning- What Went Wrong With Chantix
- How to Start Your Own Medical Practice
Top Physician Opportunities



Journal of Medicine Sign Up
Get the Journal of Medicine delivered to your inbox.
In This Issue
- The CDC's Fictitious Opioid Epidemic, Part 1
- Paying Doctors Bonuses For Better Health Outcomes Makes Sense In Theory. But Does Not Work.
- What Primary Care Doctors Really Think About Obamacare
- How Serious Damage Is Done By Scientific Fraud-JAMA Retracts Article
- Physician Participation In Executions Must Be Stopped
- Which Physician Specialties Are Happiest?
- White-Washing A Black Box Warning- What Went Wrong With Chantix
- How to Start Your Own Medical Practice
Archives
- April 1, 2025
- March 15, 2025
- March 1, 2025
- February 15, 2025
- February 1, 2025
- January 15, 2025
- January 1, 2025
- December 15, 2024
- December 1, 2024
- November 15, 2024
- November 1, 2024
- October 15, 2024
- October 1, 2024
- September 15, 2024
- September 1, 2024
- August 15, 2024
- August 1, 2024
- July 15, 2024
- July 1, 2024
Masthead
-
- Editor-in Chief:
- Theodore Massey
- Editor:
- Robert Sokonow
- Editorial Staff:
- Musaba Dekau
Lin Takahashi
Thomas Levine
Cynthia Casteneda Avina
Ronald Harvinger
Lisa Andonis


Leave a Comment
Please keep in mind that all comments are moderated. Please do not use a spam keyword or a domain as your name, or else it will be deleted. Let's have a personal and meaningful conversation instead. Thanks for your comments!

*This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.